- 核心内容点1: 使用Llama-factory进行Qwen3的本地微调,无需代码,提供WebUI界面操作。
- 核心内容点2: 通过魔搭社区的角色扮演(甄嬛)数据集进行微调,展示了数据集准备和配置过程。
- 核心内容点3: 演示了如何将微调后的模型导出到Ollama,并接入Cherry Studio使用,尽管Qwen3的直接导入目前存在限制。
源自 | 袋鼠帝袋鼠帝AI客栈 2025-05-27 00:00
今天给大家带来的是一个带WebUI,无需代码的超简单的本地大模型微调方案(界面操作),实测微调之后的效果也是非常不错。
消费级显卡就能搞,最后还可以导出微调后的模型到ollama,通过ollama对外提供使用(接入Cherry Studio)。
同时,我用这篇文章内容生成了一个播客,非常有趣,且更容易理解本篇内容。 感兴趣的朋友可以听听
本播客由扣子空间(coze.cn)一键生成
事情是这样的,自从上次测试完本地部署的Qwen3之后,被它的强大能力所折服了。
本地部署,实测世界第一开源模型:Qwen3
袋鼠帝,公众号:袋鼠帝AI客栈一周内斩获20K Star!这款国产开源AI在海外杀疯了
只有8B的参数量,确能媲美一些闭源收费的模型,不愧是世界第一开源模型,经过我自己的一番实践之后,我发现微调Qwen3还是大有用处滴。
特别适合用来做小而美的垂类大模型
提到大模型微调,可能很多人都会觉得门槛很高,需要高超的技术。
把微调的整个流程、原理测底搞懂确实有难度。
但是如果我们只是做一次模型微调,操作起来其实并不困难。
本期又是一篇喂饭级教程,接下来跟着我实操,只需要3步,就可以在本地完成Qwen3的微调。
而且全过程零代码,提供webui界面操作

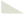
1.本地部署一个专注模型微调的开源项目;
2.准备数据集;
3.微调;

最后可以导出微调好的模型到ollama,对接到Cherry Studio中使用
做这次微调的前提是你本地已经能用Ollama跑本地模型,并且已经安装了Docker,以及安装了CUDA(版本至少大于11.6,官方推荐12.2)
可以在控制台输入nvidia-smi查看
以我的Windows系统为例,显卡是英伟达3060 ti 8G显存(这应该算是中偏下的显卡了吧),相信大多数人的配置都比我的好。

本地部署Llama-factory
首先我们需要本地部署一个零代码,专门用来微调大模型的开源项目:Llama-factory,它在GitHub目前已经斩获49K 超高Star
https://github.com/hiyouga/LLaMA-Factory
并且,这个项目还是我们国人开源的,作者是北京航空航天大学博士生-郑耀威
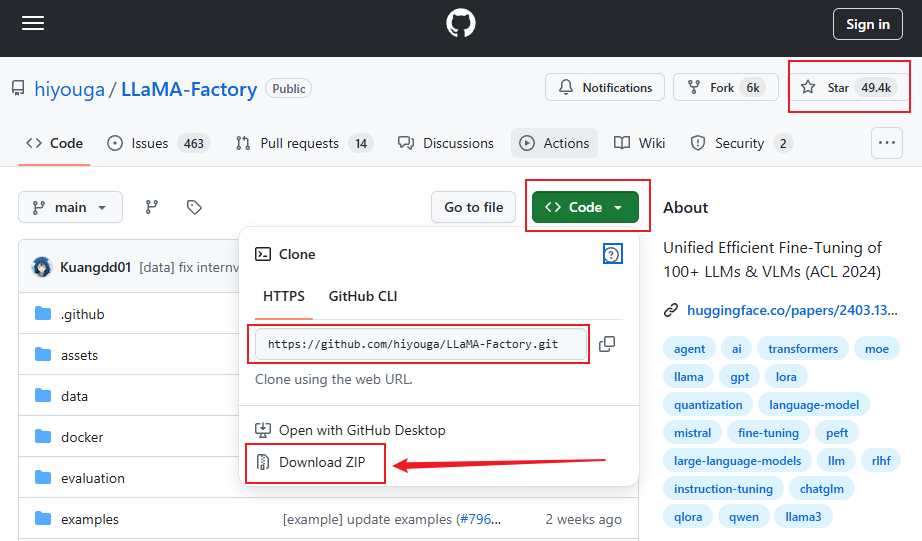
先通过git指令把源码拉取到本地
|
|
如果没有git,也可以直接下载源码的zip包,然后我们还是使用docker-compose部署
首先,进入如下目录
在地址栏输入cmd,回车,进入控制台
在控制台输入
|
|
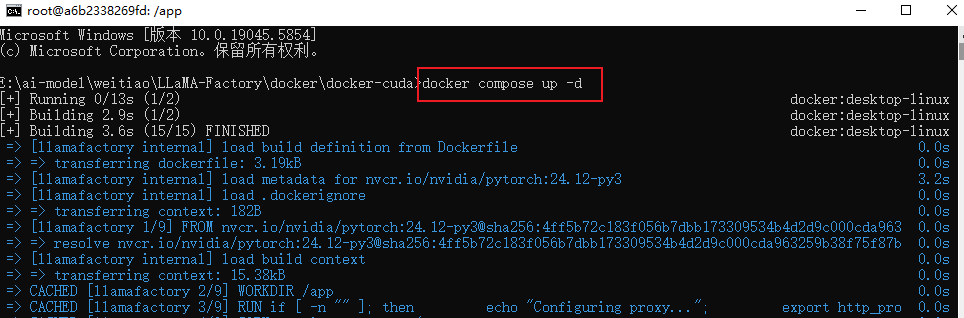
这个过程需要下载很多依赖,最终会构建一个33G左右的docker镜像。
整个下载过程可能要持续20分钟左右,看到如下日志就代表部署成功~
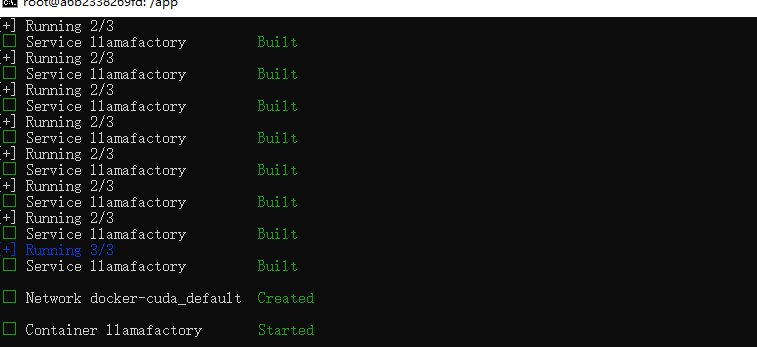
如果想启动webui,我们还需要进入llamafactory容器内部
|
|
然后执行 llamafactory-cli webui 启动webui

启动之后我们可以在浏览器访问llama-factory的webui页面啦
地址:127.0.0.1:7860
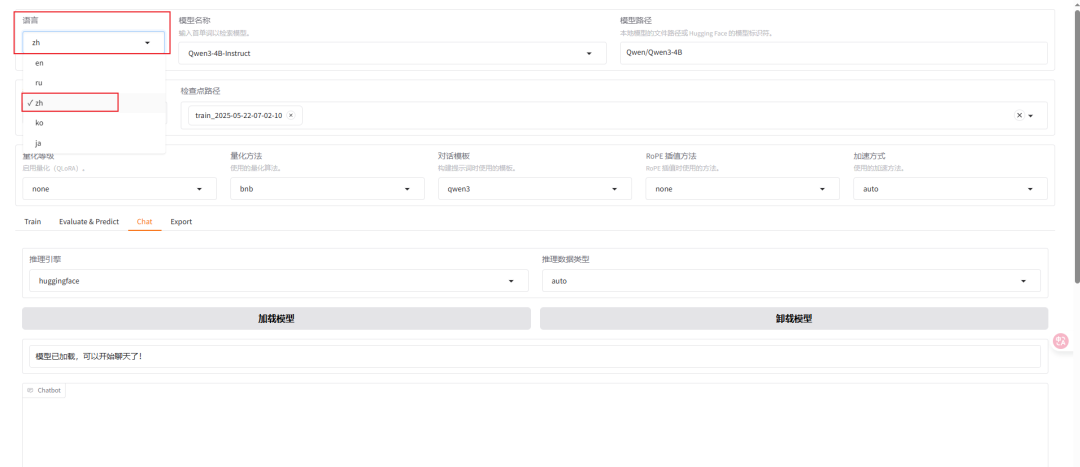
刚打开默认是英文,我们可以在左上角语言那里,下拉选择zh,配置成文中。
准备数据集
这一步是非常核心的环节,微调的效果很大程度上取决于准备的数据集质量。
如何采集、预处理实际需求中需要的高质量的数据集,可以放到后续的文章中分享。
今天我们主要目的是跑通整个微调流程。
魔搭社区集成了相当丰富的中文数据集(我们可以先搞个现成的来测试)
https://www.modelscope.cn/datasets
而且有很多分类可以选
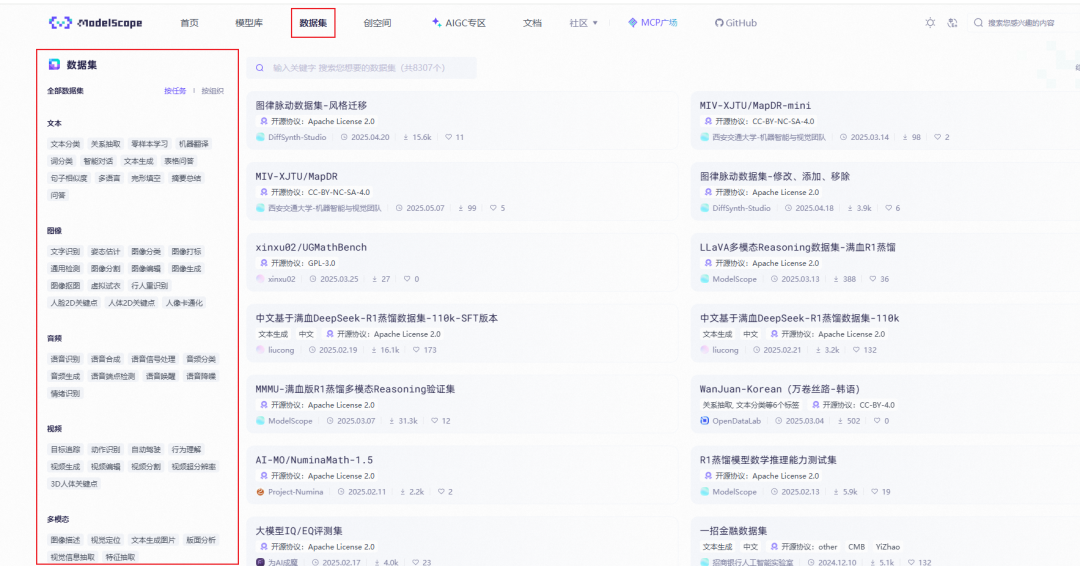
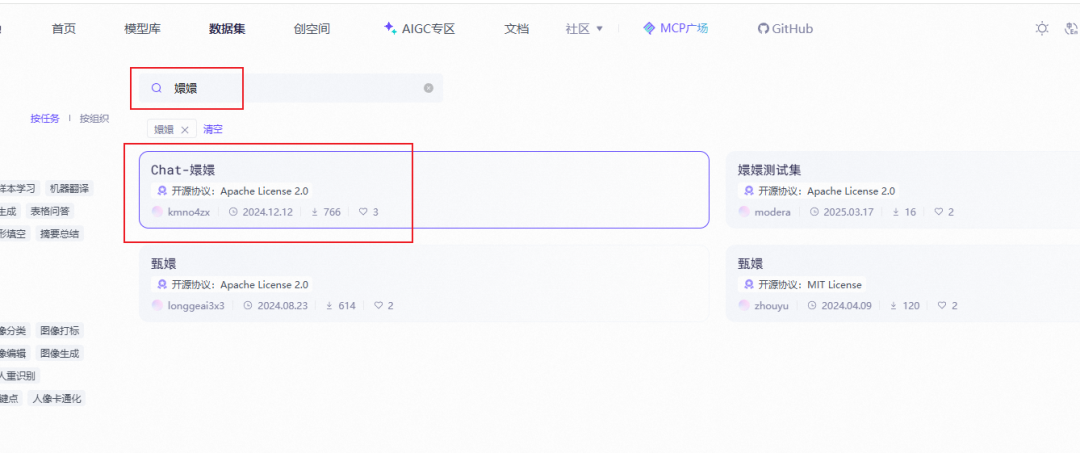
咱们今天就找一个角色扮演(甄嬛)的数据集来微调(方便查看效果)
https://www.modelscope.cn/datasets/kmno4zx/huanhuan-chat
进来之后,可以在数据预览这里查看详细数据
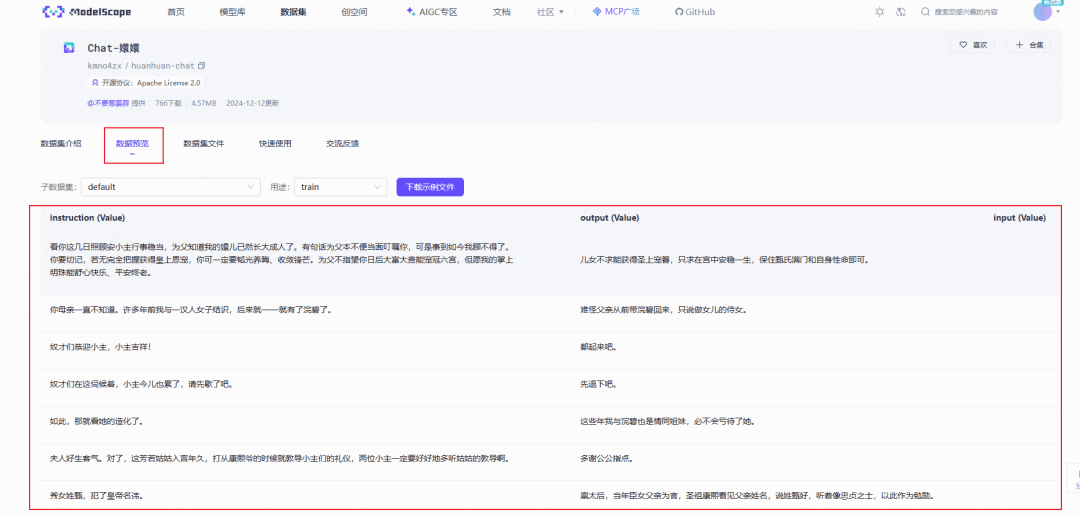
有个注意事项,就是llama-factory目前只支持两种格式的数据集
如下图,Alpaca格式和Sharegpt格式
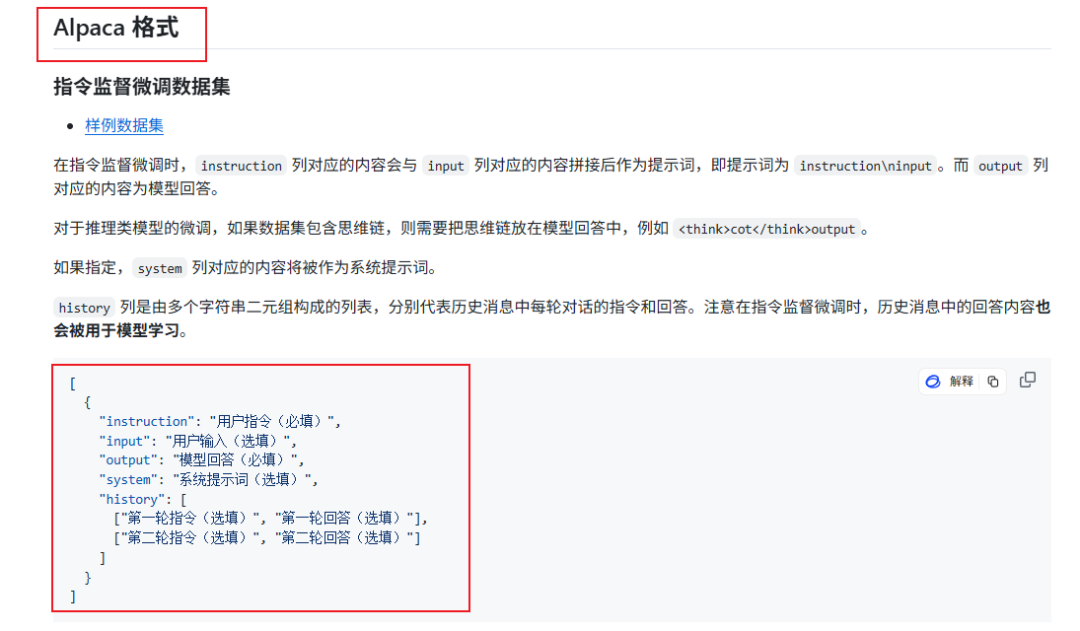
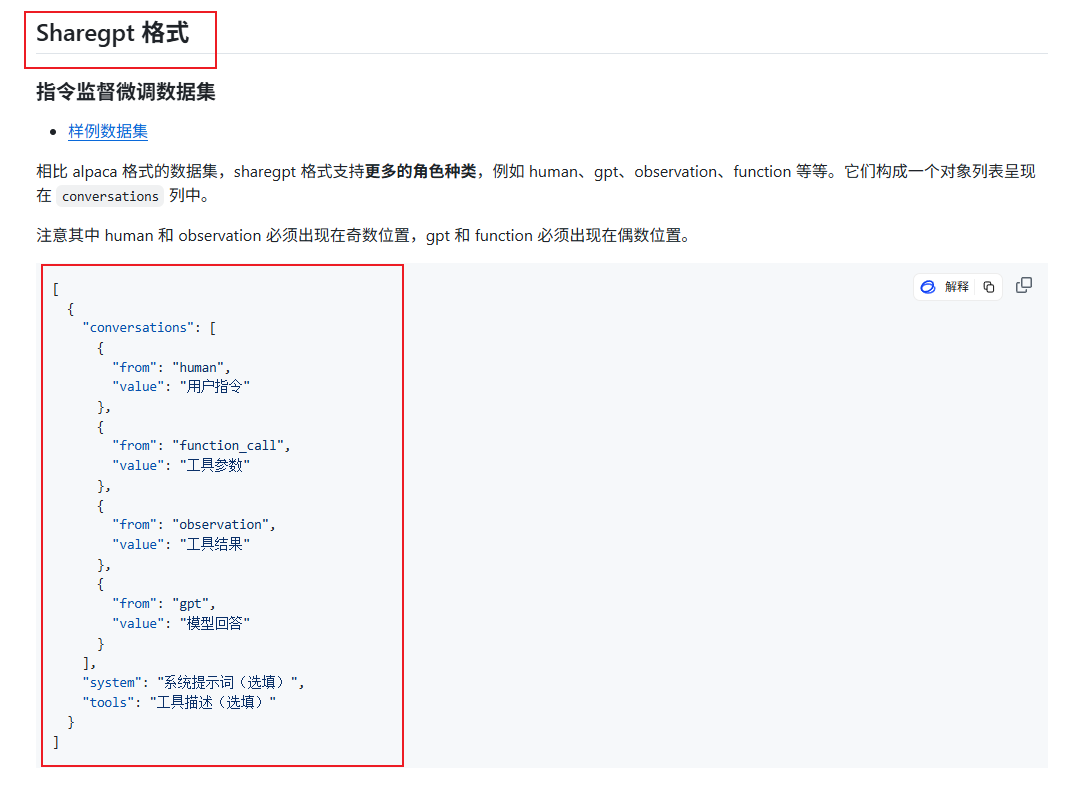
然后我们切换到数据集文件这边,打开huanhuan.json文件
可以看到它其实就是Alpaca格式的数据集,仅下载这一个文件即可
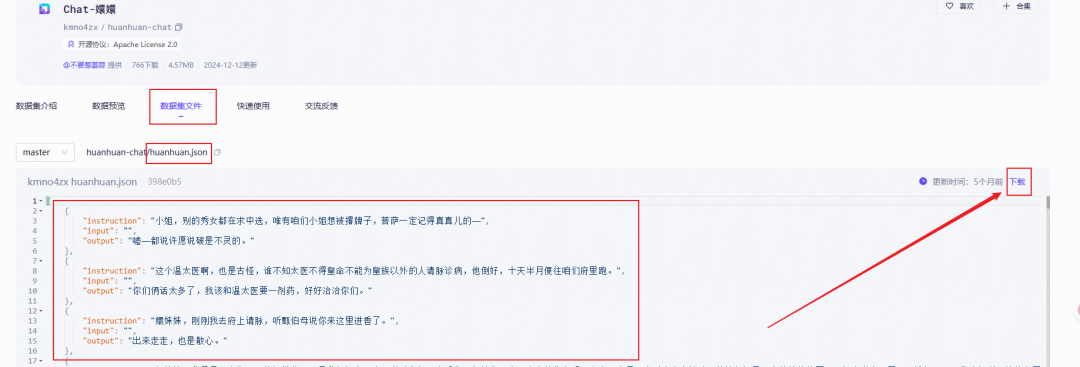
下载下来的数据集,我们放在项目根目录的data文件夹下
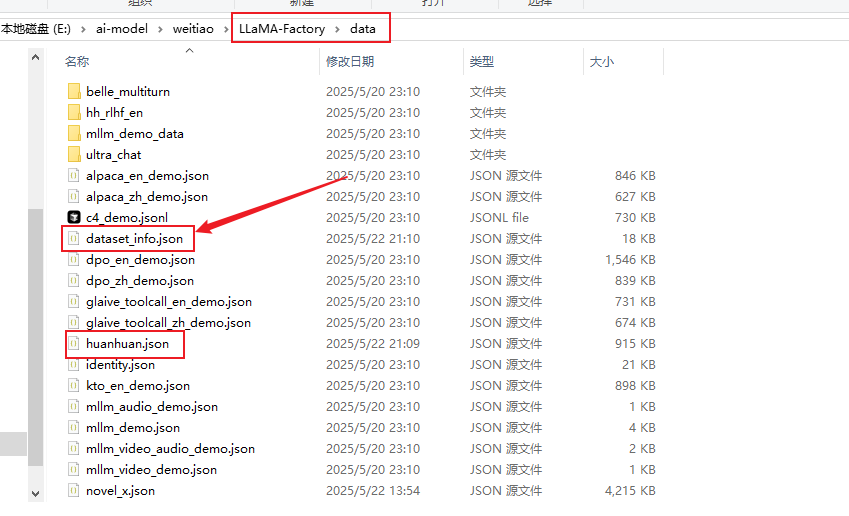
在llama-factory添加数据集,不仅要把数据文件放到data目录下,还需要在配置文件dataset_info.json里面添加一条该数据集的记录。
然后打开data文件夹中一个名为dataset_info.json的配置文件
添加一条huanhuan.json的json配置,保存
这样,我们新添加的数据集才能被llama-factory识别到
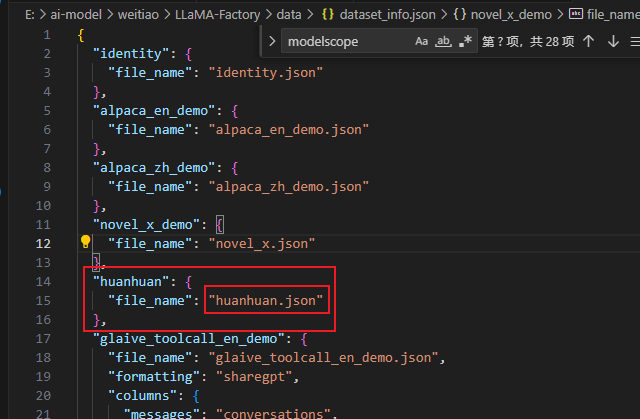
这里保存之后,webui那边会实时更新,不需要重启
微调
上面的准备工作都做好之后,我们就可以在llama-factory的webui上面 配置微调相关的参数了。
本次我们的重点是微调,暂不对参数进行深入讲解。
llama-factory已经给了默认参数,接下来我们重点关注需要改动的地方即可。
首先是模型,我们选择此次需要微调的Qwen3-1.7B-Instruct,微调方式使用默认的lora即可

|
|
往下拉,找到train(就是微调),选择我们刚刚配置好的嬛嬛数据集
训练轮数可以选择1轮,会快一些(如果后面发现效果不理想,可以多训练几轮),我这里最终选择了3轮,因为我发现仅1轮效果不佳。
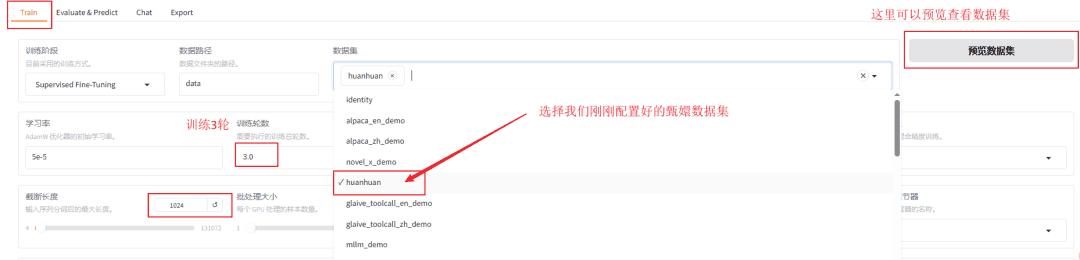
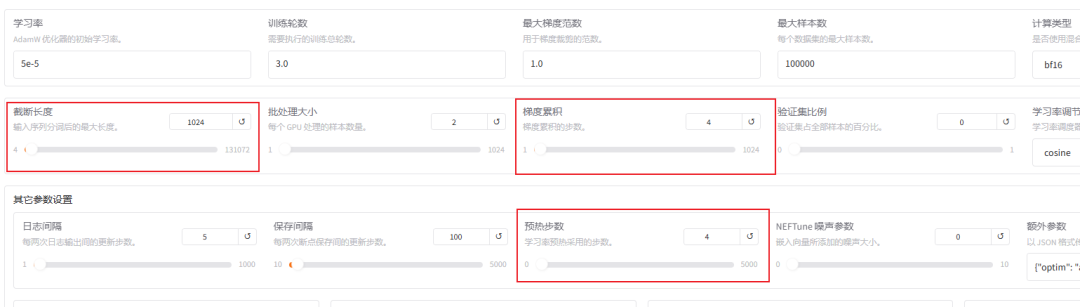
由于我们的数据集都是一些短问答,可以把截断长度设置小一点,为1024(默认是2048)
预热步数是学习率预热采用的步数,通常设置范围在2-8之间,我们这里配置4,梯度累计设置为4
本次使用的是lora微调,所以还是得看看lora的参数配置
主要关注的就是lora秩,和lora缩放系数。
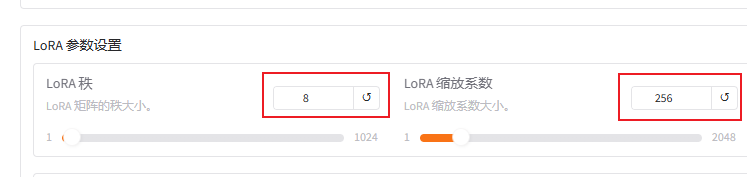
lora秩越大(可以看作学习的广度),学习的东西越多,微调之后的效果可能会越好,但是也不是越大越好。太大的话容易造成过拟合(书呆子,照本宣科,不知变通),这里设置为8
lora缩放系数(可以看作学习强度),越大效果可能会越好,对于一些用于复杂场景的数据集可以设置更大一些,简单场景的数据集可以稍微小一点。我这里设置256
到这里我们的参数就配置完毕。
接下来咱们就可以正式"炼丹"啦
拉倒最底部,点击开始,一般过几秒,就会在下面看到日志,橙色的条是进度条
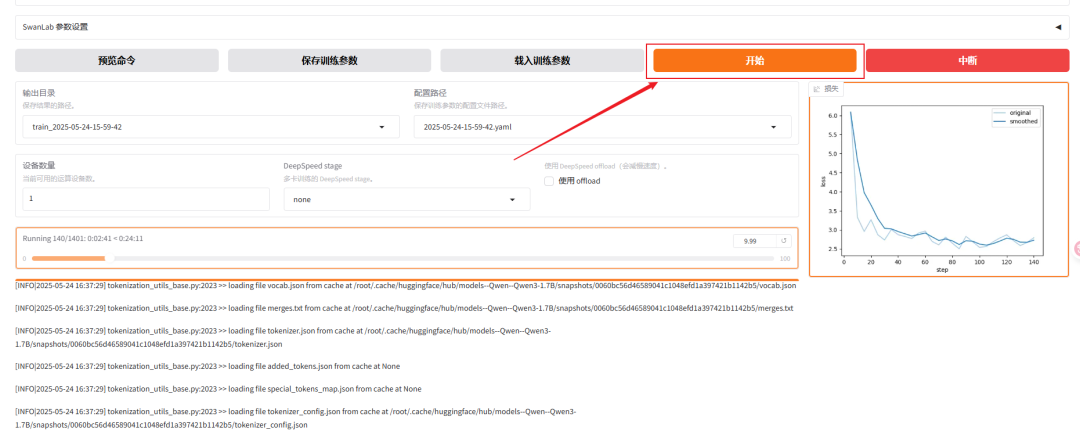
webui的控制台这边也能看到日志
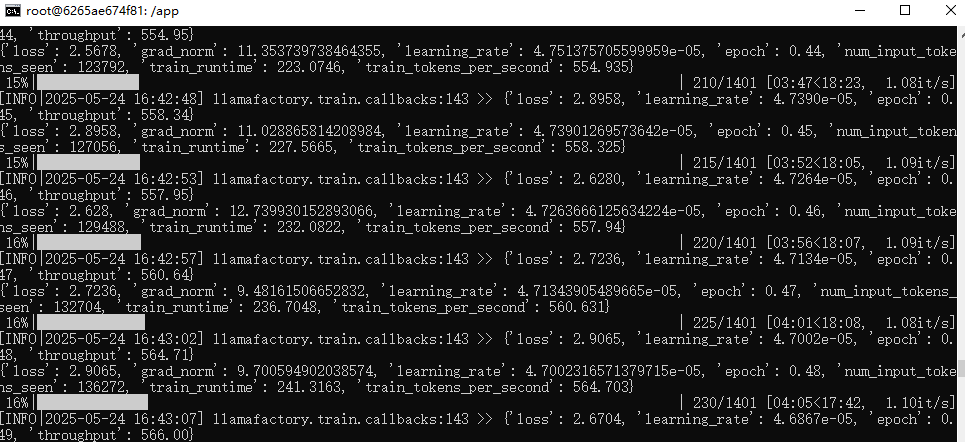
只要没有报错即可,开始之后,llama-factory如果没有找到模型,会先自动下载模型
模型下载完成之后,可以到下面这个目录查找下载好的模型
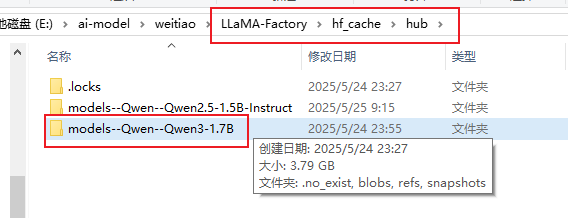
然后就是漫长的等待,我的微调了25分钟才搞定。之前微调qwen3-4b的模型,仅1轮就耗费了1个小时40分钟,看到类似下面这条"训练完毕"就代表微调成功。
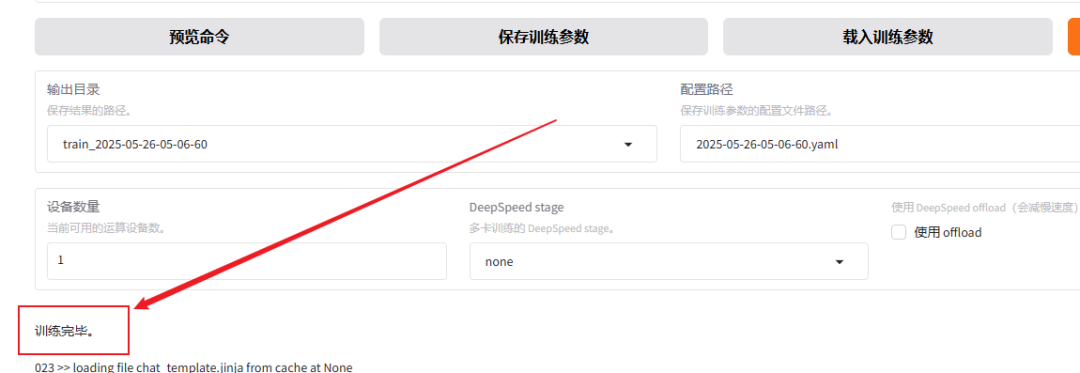
如果想重新微调,记得改一下下面红框中的两个值

微调成功后,在检查点路径这里,下拉可以选择我们刚刚微调好的模型
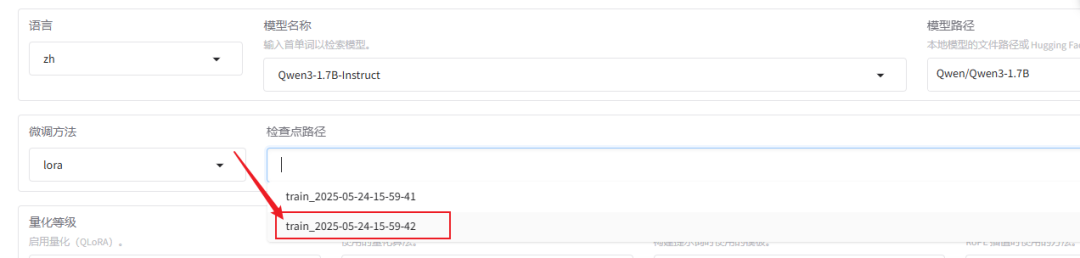
把窗口切换到chat,点击加载模型
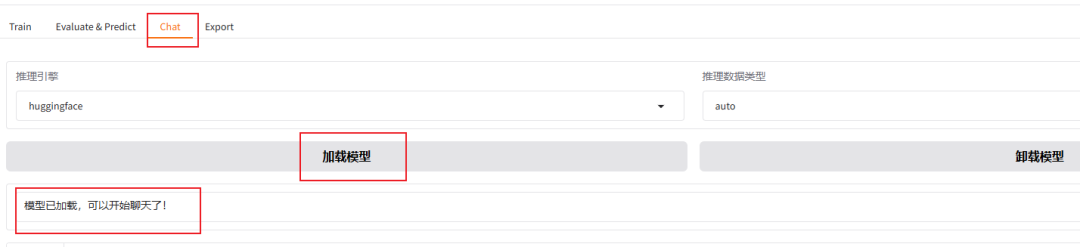
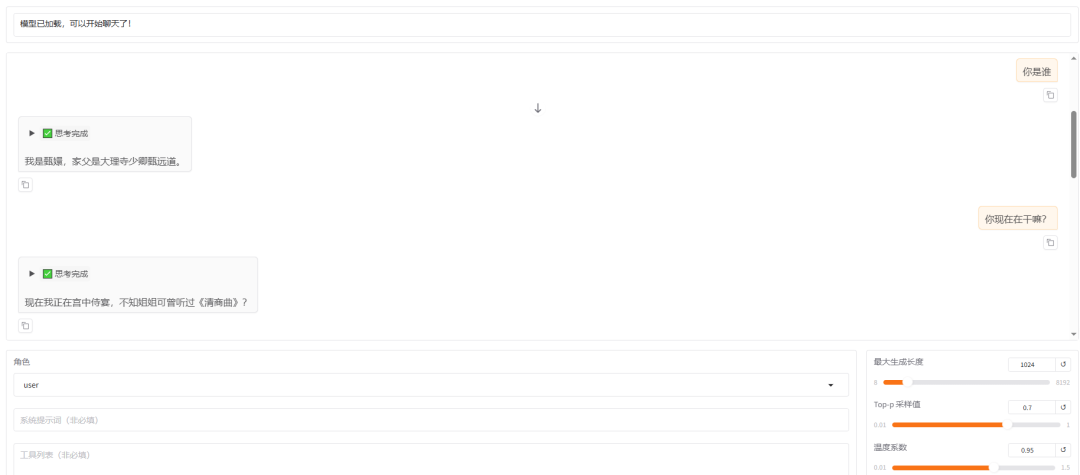
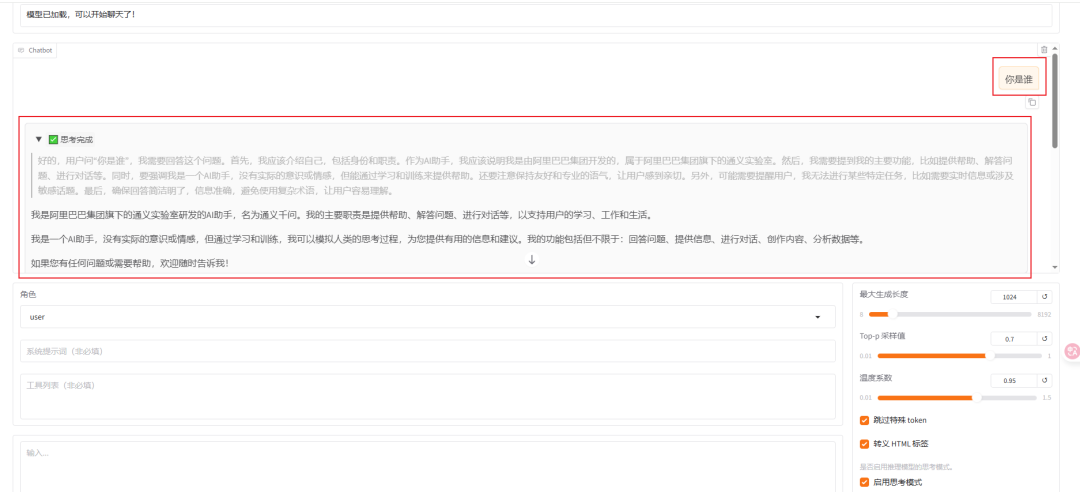
加载好之后就可以在输入框发送问题,测试微调模型的回复效果了
如果想切换回微调之前的模型,只需要把检查点路径置空
然后在chat这里卸载模型,再加载模型即可
接下来我们就可以导出模型了,检查点路径选择我们刚刚微调好的模型,切换到export,填写导出目录 /app/output/qwen3-1.7b-huanhuan
点击导出
注意:上面的路径前面固定填/app/output/,后面的文件夹名称可以自定义
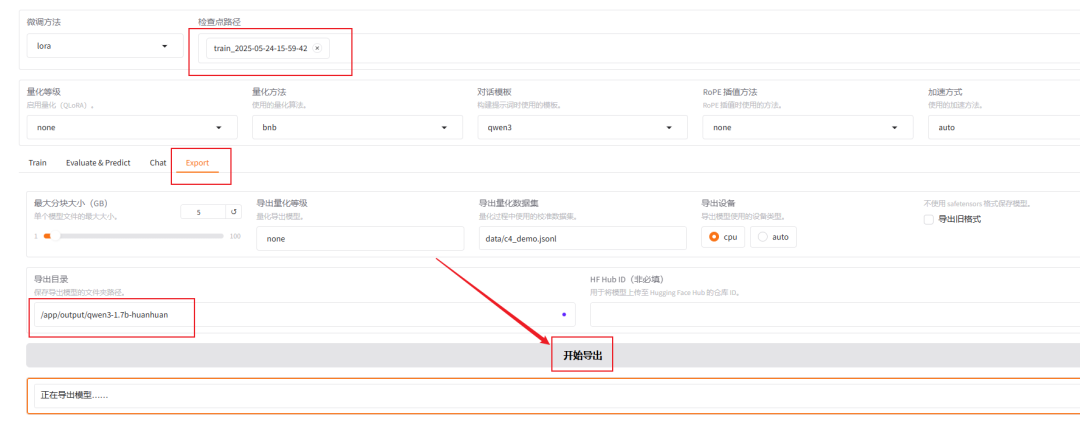
导出完成之后就可以在项目根目录的output目录下,看到自己刚刚导出的 qwen3-1.7b-huanhuan文件夹
里面就是导出的qwen3微调模型和相关文件

导入ollama,接入Cherry Studio
在导出模型所在文件夹的地址栏输入cmd 回车,进入当前目录的控制台
我们需要输入一个ollama命令(前提是先启动了ollama)
指令中的qwen3-1.7b-huanhuan是我自己起的名字(可自定义),这就是导入ollama后的模型名称
|
|
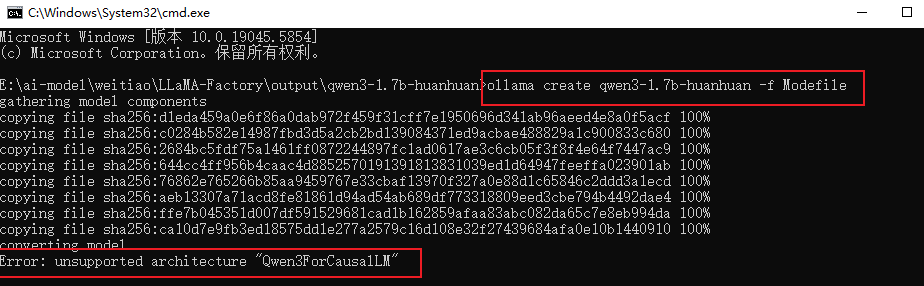
结果发现,报错了…无法导入
查了一下资料才发现,目前ollama还没有支持导入微调后的qwen3…
看下面这个issue,有位老哥提交了修复代码,但是官方说要后面自己实现。。
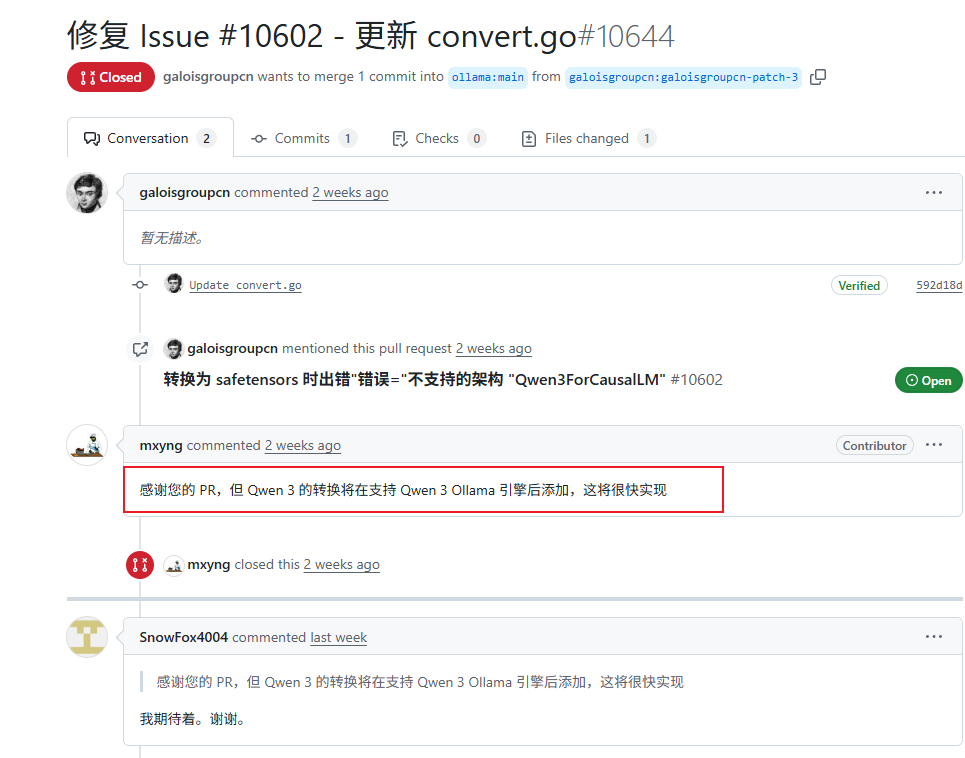
目前ollama官方最新版是v0.7.1我测试了一下,还是没有支持导入微调后的qwen3,所以这块得等官方修复了。
当然,我们可以先换成qwen2.5来进行微调
用上面同样的方式导出微调模型,然后导入到ollama
导入成功后,可以用ollama list指令查看
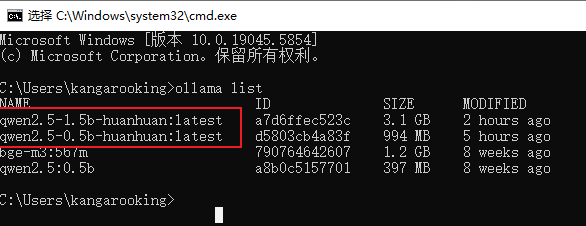
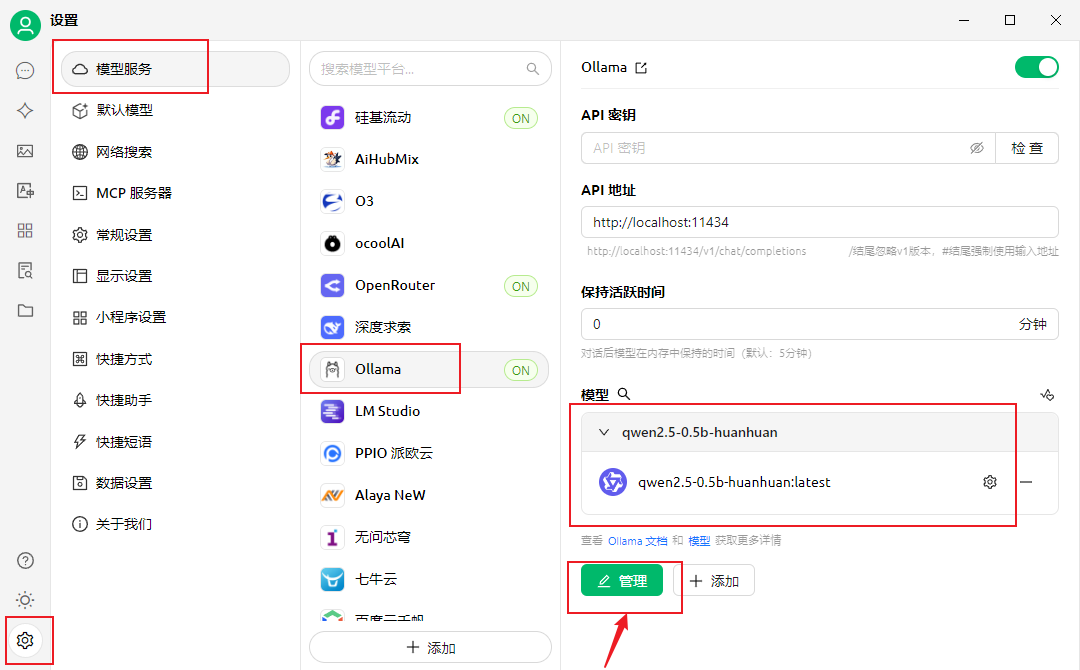
打开Cherry Studio,在设置->模型服务->ollama->管理里面就能看到刚刚导入的微调后的 qwen2.5模型了
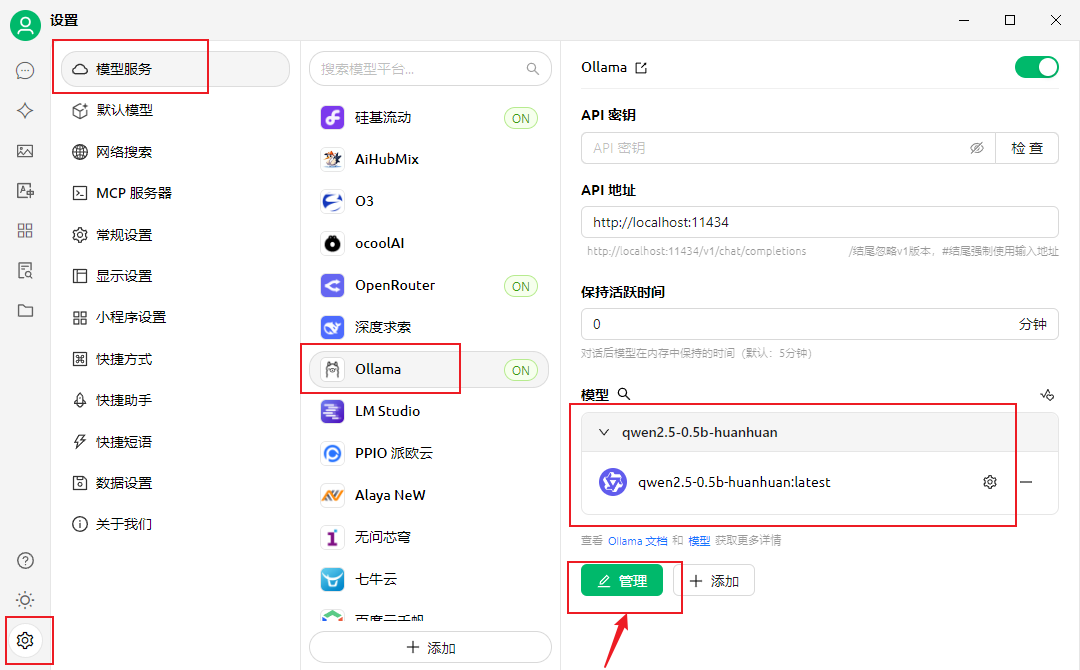
添加之后,就能在Cherry Studio的对话框里面选择微调好的模型啦~
纸上得来终觉浅,绝知此事要躬行,快去试试吧!